在科研与工程应用中,大量时序信号分类任务长期受制于高昂的人工标注成本,导致模型训练周期长、迁移能力有限。
近日,北京积算科技有限公司(以下简称“积算科技”)全新上线自监督分类模型LightningClassifier,打破传统方法对海量人工标注数据的依赖,仅需少量标注样本,即可实现约98%的分类准确率,人工标注成本降低约60%,为复杂时序数据分析提供高效方案。该模型现已上线至积算科技算力服务平台,并开放免费试用。用户只需登录平台,通过图形化界面和低代码方式,即可直接调用自监督分类模型能力。
在科研与工程领域,分类模型的性能高度依赖于大规模高质量标注数据。故障诊断、医疗分析、信号识别等时序数据分类任务,长期受困于人工数据标注成本高、耗时长的难题,不仅推高研发成本、拖慢落地速度,还导致模型泛化性弱,难以适配新场景。
LightningClassifier模型成功解决了这一难题,在数据依赖、模型性能、泛化能力上实现三重突破,具体来说:
大幅降低标注依赖,显著降低成本。模型采用“自监督预训练+少量标注微调”的双阶段模式,训练初期可充分挖掘海量未标注时序数据的价值,自主学习信号中的核心特征结构与规律,无需人工逐一对数据打标,仅需少量标注样本即可完成高精度微调。相比传统监督学习模型,可降低约60%的人工标注成本,尤其适用于标注门槛高、专业度要求强的场景。
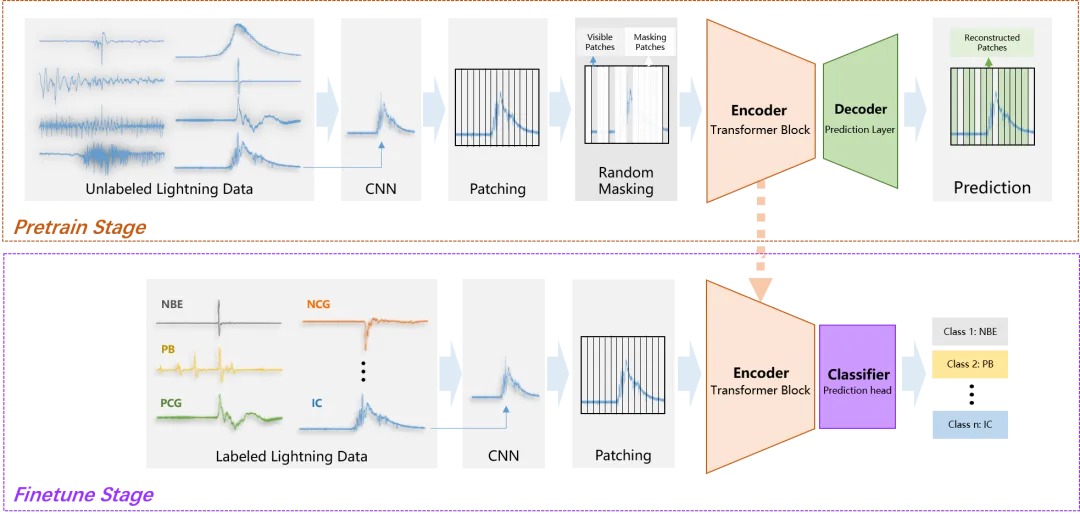
图1 LightningClassifier模型架构
准确率与效率双优,性能表现突出。模型在北京市闪电波形数据集上,仅使用几千条标注样本,就实现了98.30%的分类准确率,远超传统方法的性能上限。同时训练流程高效简洁,可快速完成模型训练与测试,缩短研发周期。
跨场景泛化能力强,适用范围广泛。模型在迁移至两个独立公开数据集后,分类准确率仍分别保持97.94%与98.29%,稳定性出色。模型适用于全行业一维时序信号处理,覆盖设备状态监测、电磁信号解析、生物医疗筛查、资源勘探识别等多元方向,为不同领域的科研与工程任务提供高效支撑。
目前,LightningClassifier已上线至积算科技算力服务平台并开放免费试用。用户远程登录平台后,通过图形化界面和低代码方式,即可免费调用LightningClassifier快速完成分类模型训练与测试。
平台已配置LightningClassifier专属环境。用户使用模型中的闪电波形数据并运行预设脚本,即可尝试闪电分类模型的预训练和微调。用户也可上传自己的数据,实现个性化的分类模型训练与测试。
简单三步,快速体验:
https://www.icompify.com/inform_zhuce.thtml?sessionid=(请复制到浏览器内打开)
积算科技诞生于全球生成式AI浪潮,专注于智能算力服务市场,致力于成为中国最具价值的智能算力服务商,聚焦互联网、运营商、高校、新能源汽车等领域的多家头部客户提供算力服务。公司拥有万卡级先进智能算力资源池,提供裸金属、智能算力系统、专属智能算力系统等算力服务产品,适用于大模型训练与推理、算法研究、大数据分析、自动驾驶、智能科学计算等多元场景。其运维和服务团队具备大规模智能算力系统设计建设、大模型开发应用及性能优化能力,可提供全栈大模型应用开发服务支持,并根据客户需求提供灵活服务模式。
注:本研究中相关研究成果已在地球物理学领域国际顶级期刊《Geophysical Research Letters》上发表。涉及的模型架构与代码已公开在Zenodo存储库中,供学术和研究社区公开使用。我们鼓励基于本研究工作的进一步探索与应用。为保障原创工作的恰当认可,如您在使用本模型或代码于任何出版物、报告或衍生项目中,敬请标明出处并引用我们的原始论文及Zenodo数据集。









