转载自:月之暗面Kimi
今天,我们发布并开源 Kimi K2.6 模型,带来行业领先(state-of-the-art)的代码、长程任务执行和 Agent 集群能力。

( 完整基准测试成绩见技术博客 )
Kimi K2.6 的通用 Agent、代码、视觉理解等综合能力得到全面提升,其中在博士级难度的完整版人类最后的考试(Humanity's Last Exam)、在考察模型真实软件工程能力的 SWE-Bench Pro、评估 Agent 深度检索能力的 DeepSearchQA 等基准测试中均取得行业领先的成绩,持平或优于 GPT-5.4、Claude Opus 4.6 和 Gemini 3.1 Pro等闭源模型。
Kimi K2.6 是我们迄今最强的代码模型,其长程编码能力也得到显著提升,在测试中可以不间断编码 13 小时,编写或修改超过 4000 行代码,完成复杂系统的开发和优化。通过将代码与视觉能力的深度融合,K2.6 将代码驱动的设计能力提升到了新高度,可以交付极具设计创意的专业级 Web 应用。
Kimi K2.6 大幅增强了 Agent 自主化执行能力,帮助我们进一步扩展 Agent 的能力范围:
由 K2.6 模型驱动的「Agent 集群」架构迎来一次大升级,现在支持 300 个子 Agent 并行完成 4000 个协作步骤,实现更大规模的并行化,同时任务完成度和交付质量相比于 K2.5 有显著提升;
针对 OpenClaw、Hermes Agent 等主动式 Agent 框架,K2.6 展现出极强的自动化任务处理能力,支持长达 5 天的持续自主运行。
K2.6 在长程代码任务中的表现取得了突破,面对不同编程语言(如 Rust、Go、Python)和任务场景(如前端、运维、性能优化)均具备更可靠的泛化能力。
在涵盖了多种复杂端到端任务的、Kimi 内部严格代码评测基准 Kimi Code Bench 中,K2.6 的成绩比 K2.5 提升了约 20%。

根据我们的实测,Kimi K2.6 模型在复杂软件工程任务中,展现了强大的长程推理能力:
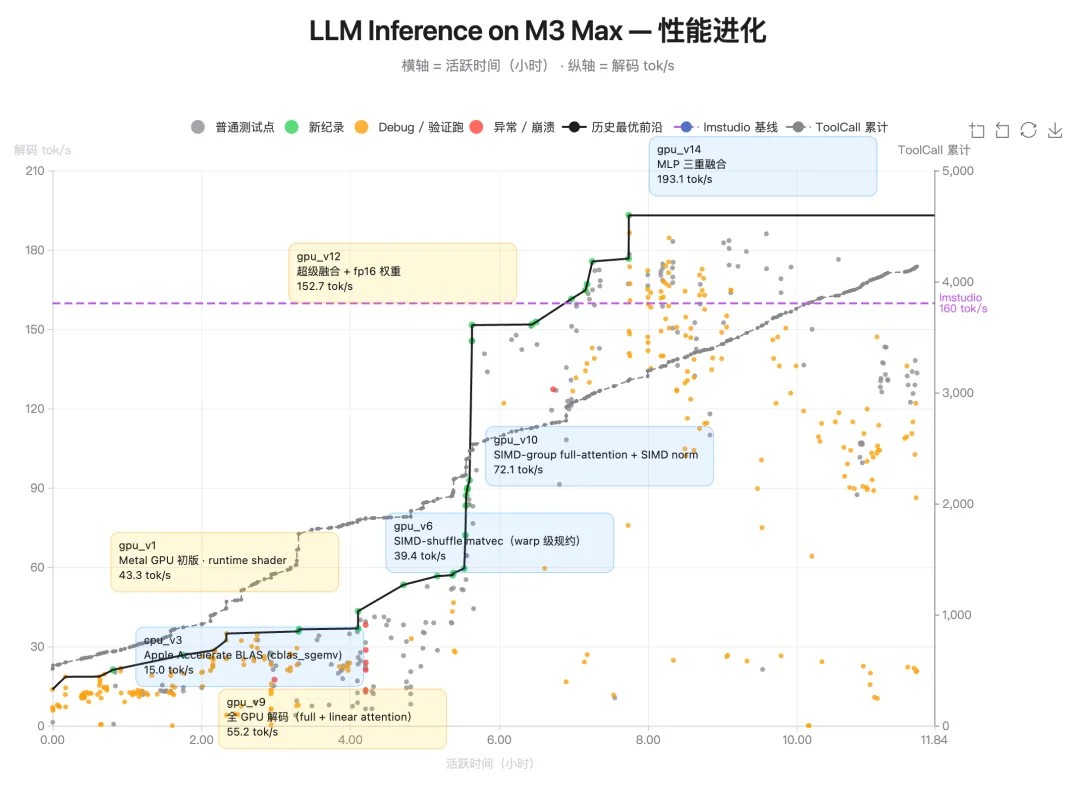
场景一:K2.6 成功在 Mac 本地下载并部署了 Qwen3.5-0.8B 模型,通过使用小众 Zig 语言实现并优化模型推理,证明了新模型的泛化能力。经过 4,000 多次工具调用,超过 12 小时的不间断运行,K2.6 模型共迭代了 14 轮,将吞吐量从约 15 tokens/s 提升至约 193 tokens/s,最终实现比 LM Studio 快 20% 的推理速度。


我们相信,美本身就是一种生产力。K2.6 Agent 模式现在可以制作极具设计感和视觉冲击力的网站。
凭借对图像和视频生成工具的熟练调用,K2.6 Agent 能够生成视觉风格高度统一的素材,构建视觉焦点突出的首屏区(Hero Section),并且实现各种交互元素和丰富的滚动触发等动效。
K2.6 Agent 不局限于写前端页面,也支持基础的后端数据库模块,例如在生成网页中嵌入表单信息收集的功能。
凭借更强的多模态编程能力,K2.6 能够更精准地将图像和视频素材转化为代码。
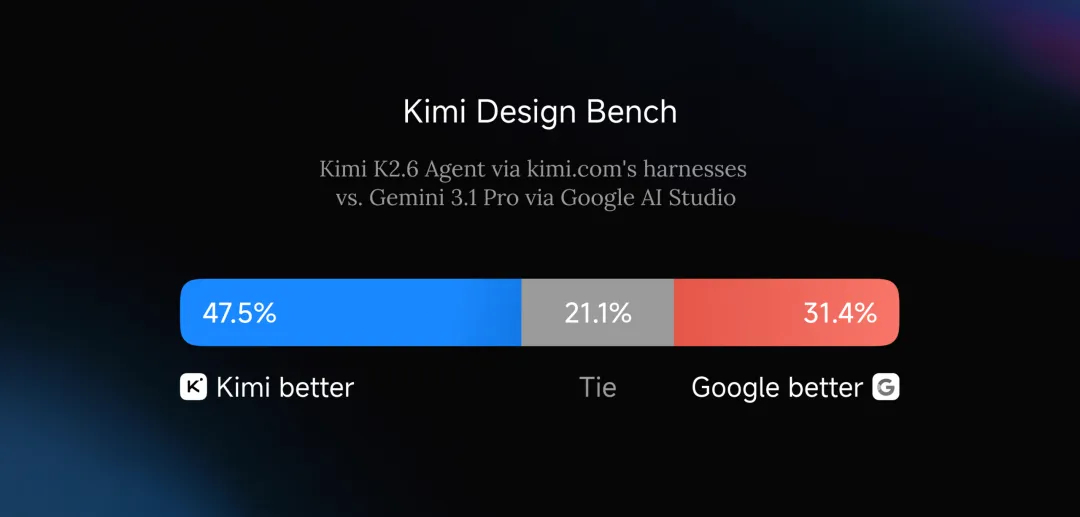
我们创建了一套专门的前端开发设计评测基准( Kimi Design Bench),涵盖视觉输入任务、落地页构建、全栈应用开发以及通用 Web 开发这四个维度。对比 Google AI Studio 中的 Gemini 3 模型,基于 kimi.com 框架的 K2.6 Agent 展现出了非常明显的领先优势。

在 K2.5 的基础上,K2.6 的 Agent 集群的协同能力全面升级。Agent 集群现在可以调度不同技能特长的 Agent 互补协作,将搜索、深度研究、文档分析和长文创作等能力进行组合,任务完成质量相比于 K2.5 有显著提升。Agent 集群在单次运行中,就能独立完成从文档到网页、再到 PPT 和表格的多产物端到端交付。
此外,Agent 集群的架构也升级了,现在最多支持 300 个子 Agent 并行完成 4000 个协作步骤,实现更大规模的并行化,进一步推高多 Agent 系统协作的能力上限。
我们看两个使用案例:
案例二:Agent 集群把一篇包含海量视觉数据的高质量天体物理论文转化为可复用的学术技能。通过提取论文的推理流程和可视化方法,系统产出了 40 页、长达 7000 字的研究论文,以及包含 2 万多条数据的结构化数据集和 14 张天文级图表。
K2.6 显著增强了 Agent 的自主化执行能力,特别是在 OpenClaw、Hermes Agent 式自动化任务中表现突出——这些场景要求 AI 能够跨应用实现 24/7 不间断运行。
与传统的对话交互不同,这类工作流需要 AI 以后台常驻 Agent 的形式主动管理任务计划、执行代码、协调跨平台操作。
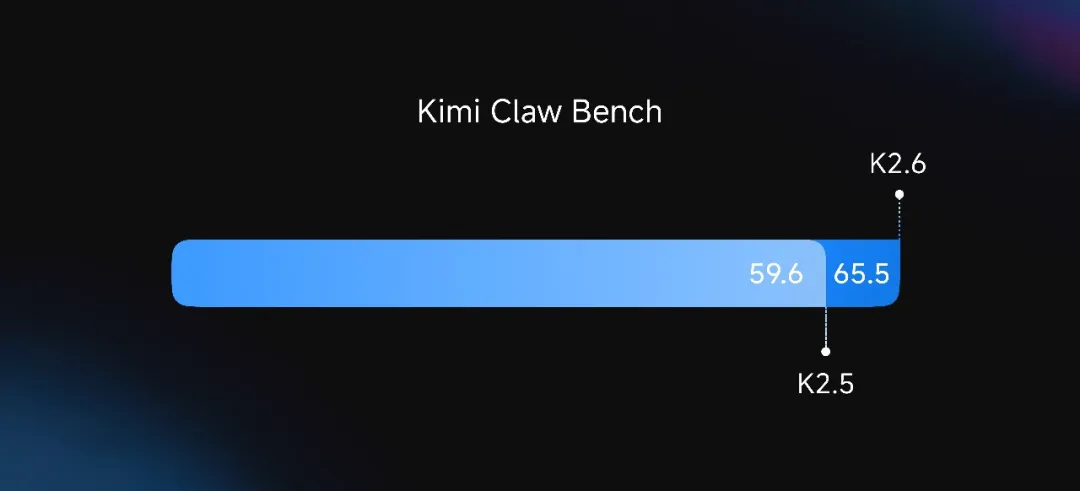
Kimi 内部的 Claw Bench 测试结果显示,K2.6 相比 K2.5 综合性能提升了 10%。这项基准测试涵盖五大维度:编程任务、即时通讯生态集成、信息检索与分析、定时任务管理,以及记忆调用能力。在所有评测指标上,K2.6 的任务完成率和工具调用准确率均领先 K2.5,在无需人工干预、需要长时间自主运行的工作流中优势尤为显著。









