

Fast-AI训练服务平台是面向人工智能训练场景的一站式AI开发、训练、推理平台,可实现容器化部署、可视化开发、数据管理、镜像仓库等,为用户提供极致高性能的AI 计算资源,实现高效的计算力支撑、精准的资源管理和调度、敏捷的数据整合及加速、流程化的AI 场景及业务整合,有效打通开发环境、计算资源与数据资源,提升开发效率。
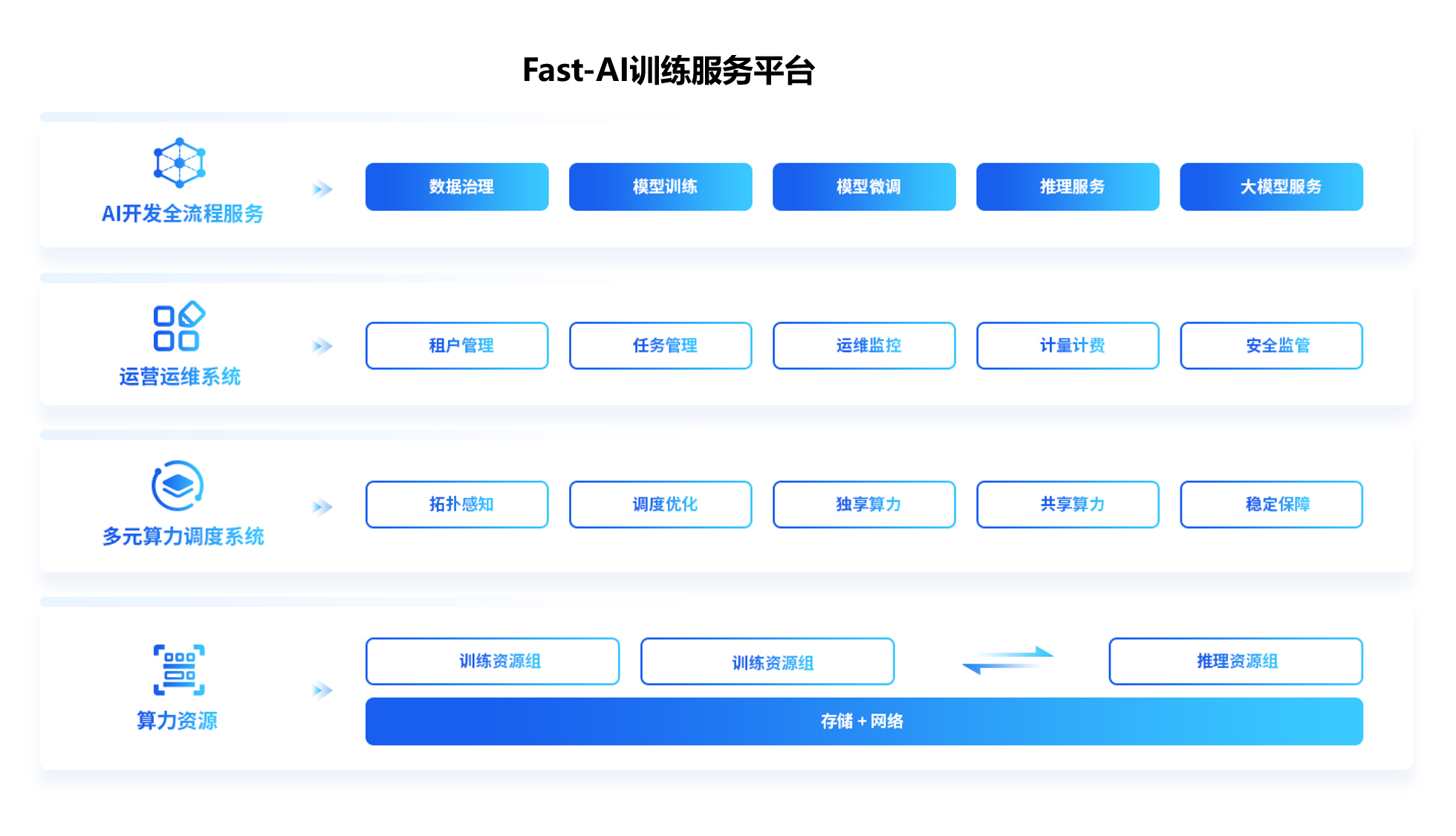


覆盖大模型预训练→微调→评估→部署→Prompt管理→Chat应用,兼容Transformer/vLLM/SGlang等框架。
端到端AI模型接入、训练、微调和推理,更快投入生产。

开发环境秒级创建,预集成10+开源大模型、内置主流AI框架 (TensorFlow, PyTorch)、开发工具 (Jupyter/shell)、Prompt工程与Chat应用,实现大模型服务的快速使用落地。

千卡级算力毫秒调度,按需分配,提升资源利用率;GPU细粒度调度,显存切片技术(支持4GB/8GB粒度),单卡24GB可拆分为3个独立切片,利用率提升40%;支持独享、共享、弹性等多种算力供给,将算力资源利用率进一步提升20%;

提供各类资源的精细化管理与调度能力,并提供CPU、GPU、网络、内存、磁盘、tensor core等十余种资源实时监控能力。

基于裸金属算力N1000,搭配人工智能开发资源平台,可实现容器化部署、可视化开发、数据管理、镜像仓库等功能,为客户提供高效、易用、可靠的AI训练服务平台,适合AI训练、推理、深度学习、机器学习等多种场景。
基于裸金属算力N1200,搭配人工智能开发资源平台,可实现容器化部署、可视化开发、数据管理、镜像仓库等功能,为客户提供高效、易用、可靠的AI训练服务平台,96G高显存适合AI训练、推理、深度学习、机器学习等多种场景。
基于裸金属算力M1000,搭配人工智能开发资源平台,可实现容器化部署、可视化开发、数据管理、镜像仓库等功能,为客户提供高效、易用、可靠的AI训练服务平台,国产类CUDA生态芯片,AI推理、深度学习、机器学习等多种场景的高性价比选择。

 AI训练支持
AI训练支持AI全流程支持:覆盖大模型预训练→微调→评估→部署→Prompt管理→Chat应用,兼容Transformer/vLLM/SGlang等框架;
交互式开发:用户通过平台可快速构建交互式AI开发环境,提供Jupyter、Webshell在线交互开发,支持对接第三方开发工具(如VSCode、PyCharm);
分布式任务:支持AI模型的多机分布式训练,可提交Tensorflow、Caffe、pytorch、PaddlePaddle、MXNet框架的分布式训练作业,并支持MPI、PS/Worker、Master/Worker、Deepspeed、Megatron等分布式类型;
推理部署服务:支持模型部署、镜像部署、原生部署(yaml)、Helm部署等部署方式,支持服务上线过程中的离线测试、流量调节、多分桶测试、在线服务评估等全流程服务管理能力,支持服务部署后对外提供http/gRPC/tcp协议的请求。
 AI服务支持
AI服务支持强大调度能力:千卡级算力毫秒调度,按需分配,提升资源利用率;
断点续训:Checkpoint整合K8s状态监控,服务器宕机/掉卡时任务自动迁移续训,中断恢复时间<5分钟;
GPU细粒度调度:显存切片技术(支持4GB/8GB粒度),单卡24GB可拆分为3个独立切片,利用率提升40%;
实时资源管理:支持以集群视图、节点视图、加速卡视图查看集群整体运行情况,提供不同层级的监控信息查看,提供GPU、CPU、内存、IB/RoCE网络、存储等关键设施的性能曲线、图表展示;
多租户管理:平台设置系统管理员、组管理员、普通用户、审计员角色,支持不用业务模块的使用权限控制,支持业务流程审批,支持用户的资源配额设置,支持用户的批量管理;

